OpenAI released an advanced image generator for GPT‑4o this week.
The San Francisco-based research lab announced that this improvement in image generation is now native to GPT-4o, allowing users to refine images through natural conversation.
“GPT‑4o can build upon images and text in chat context, ensuring consistency throughout. For example, if you’re designing a video game character, the character’s appearance remains coherent across multiple iterations as you refine and experiment,” explained the company.
This initial release is available across ChatGPT Plus, Pro, Team, and Free subscription tiers. The free tier’s usage limit is the same as three images per day with DALL-E.
This model is considered a step change from previous models as it uses GPT-4o unimodal, a foundation that can generate data, including text, images, audio, and video.
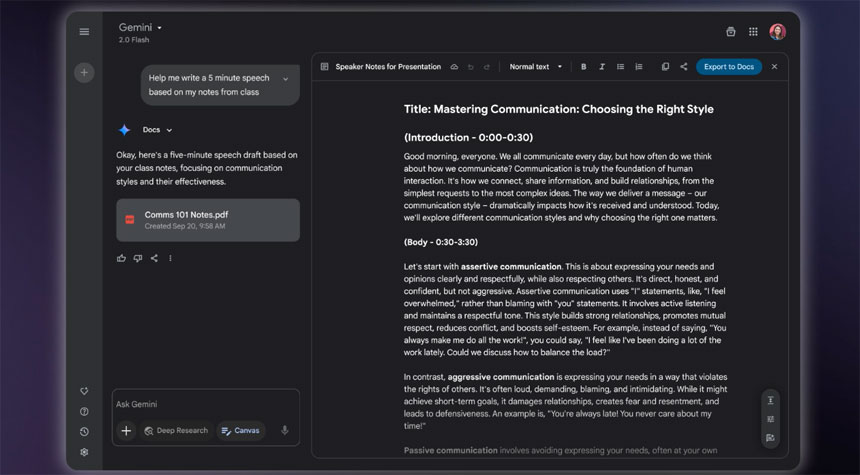
Google added this week a dedicated workspace to its Gemini chatbot called Canvas, an identical name used by OpenAI for the same feature – and similar to Anthropic’s Artifacts.
It’s an interactive space where users can refine documents, create and debug code, and share writing and coding projects while using Gemini’s feedback to suggest edits and adjust the tone, length, or formatting.
Canvas also streamlines the process of transforming coding ideas into working prototypes for web apps, Python scripts, games, simulations, and other interactive apps.
It can also generate and preview HTML/React code and other web app prototypes to visualize the design, such as a website’s email subscription form.
This feature works by selecting Canvas in the prompt bar and start creating. Google created a dedicated website.
Gemini’s Canvas includes the Audio Overview of NotebookLM, which went viral last year. It transforms users’ files into realistic-sounding podcast-style discussions between two AI hosts, with audio summaries of documents, web pages, and other sources.
Uploading a document via the prompt bar triggers the Audio Overview shortcut. Once a summary is generated, it can be downloaded or shared via the Gemini app on the web or mobile.
Canvas ux is becoming the standard for interacting with LLMs on documents
Notes on today’s DeepSeek v3 0324 model – a 641 GB MIT licensed monster, but you can run it on a ~$10,000 consumer level 512GB M3 Mac Studio if you use the 352 GB quantized version via MLX https://t.co/OnCoHsyZLB
The software giant also introduced a new program intended, in part, to help businesses “migrate off legacy CRM vendors,” without citing Salesforce by name in that case.
Microsoft wants to “empower every employee with a Copilot and transform every business process with agents” and “apply this ambition to sales, the revenue engine for every business.”
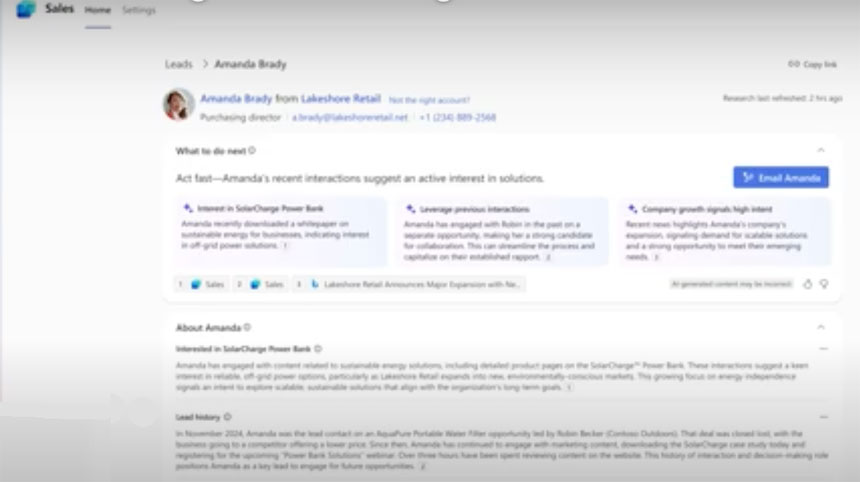
Sales Agents can work autonomously by researching and identifying potential customers, setting up meetings, and contacting and following up on leads. It can complete some basic sales independently. The agents gather information from customer databases and CRM and company data like pricing sheets, the web, and Microsoft 365—such as emails and meetings—to personalize every response.
Sales Chat gives sales reps summaries, actionable takeaways, and insights from CRM data, pitch decks, meeting notes, emails, and the web. It works with simple prompts like “Give me a list of deals that are at risk of falling through,” “What should I know going into tomorrow’s meeting with this customer?” or “Help me create a plan to close this deal.”
Its CEO, Marc Benioff, has criticized Microsoft’s AI initiatives while rolling out Salesforce’s competing Agentforce platform.
Benioff has called Microsoft a “reseller of OpenAI.” He also criticized Microsoft’s Copilot, comparing it to the infamous “Clippy” assistant and suggesting it exposes user data to security risks.
Oracle, IBM, and ServiceNow are among the other major companies developing and offering agentic AI technology for sales and business applications.
Columbia University agreed yesterday to the Trump administration’s list of demands to start negotiations on restoring $400 million in federal funding for medical and scientific research projects.
On March 7, the U.S. Government canceled the university’s federal grants, accusing the New York-based institution of “inaction in the face of persistent harassment of Jewish students.”
The Trump administration had ordered the school to implement a mask ban at protests, discipline protesters, and reform admissions, among other demands.
Columbia University was seen as the epicenter of student-led pro-Palestinian demonstrations that overtook life at college campuses nationwide.
Yesterday, the institution agreed to ban students from wearing masks at protests, hire 36 new campus security officers who will be able to arrest students and appoint a new senior vice provost to oversee the Department of Middle East, South Asian, and African Studies.
Columbia also committed to “greater institutional neutrality” and “working with a faculty committee to establish an institution-wide policy implementing this stance.” The university added that it will review its admissions procedures to “ensure unbiased admission processes,” as the Trump administration requested.
On Thursday, 41 of theroughly 100members of the university’s history department warned the university against allowing the administration to interfere in its policy. They compared the administration’s actions to attempts by “authoritarian regimes” to seek control over independent academic institutions.
Amid the negotiations over the grants, federal immigration officials apprehended at least two Columbia students who participated in the student-led protest, including 30-year-old Mahmoud Khalil. A doctoral student from India, Ranjani Srinivasan, also fled to Canada after her student visa was revoked.
President Trump signed a long-awaited executive order on Thursday that begins the process of dismantling the U.S. Department of Education, fulfilling a longstanding campaign promise to conservatives.
The order is designed to leave school policy almost entirely in the hands of states and local boards, a prospect that alarms liberal education advocates.
Surrounded by schoolchildren seated at desks in the East Room of the White House, President Trump cited poor test scores as a key justification for the move.
He instructed Education Secretary Linda McMahon to begin shutting down her agency. According to Article I of the Constitution, this task cannot be completed without congressional approval.
However, Trump also said Thursday that the department would continue to provide critical functions required by law, such as administering federal student aid, including loans and grants, funding special education and districts with high levels of student poverty, and continuing civil rights enforcement.
Since taking office, Trump has slashed the department’s workforce by more than half and eliminated $600 million in grants.
“This is political theater, not serious public policy,” said Ted Mitchell, the president of the American Council on Education, an association that includes many colleges and universities in its membership. “To dismantle any cabinet-level federal agency requires congressional approval, and we urge lawmakers to reject misleading rhetoric in favor of what is in the best interests of students and their families.”
Lawyers for supporters of the Education Department anticipated they would challenge Mr. Trump’s order by arguing that the administration had violated the Constitution’s separation of powers clause and the clause requiring the president to take care that federal laws are faithfully executed.
Senator Bill Cassidy, a Louisiana Republican who chairs the chamber’s Health, Education, Labor and Pensions Committee, said he would submit legislation to eliminate the Education Department.
“I agree with President Trump that the Department of Education has failed its mission,” Cassidy said.
“Since the department can only be shut down with congressional approval, I will support the president’s goals by submitting legislation to accomplish this as soon as possible.”
Under the Biden administration, the department was criticized as being deferential to teachers’ unions and overreaching on specific issues, such as student loan forgiveness and its interpretations of civil rights laws on behalf of transgender students.
Nontechnical hobbyists without code knowledge are starting to build fully functional apps and websites by typing prompts into AI-driven text boxes in a trend called vibecoding.The term vibecoding has been popularized by the AI researcher Andrej Karpathy, as he explained in this post.
There’s a new kind of coding I call “vibe coding”, where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It’s possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper…
An expert explained in The New York Times that these aren’t the kinds of tools that a big tech company would build. “There’s no real market for them; their features are limited, and some of them only sort of work.”
These creations range from tools that transcribe and summarize long podcasts to searchable web databases or practical organization apps.
“Building software this way produces a feeling of AI vertigo, similar to what I felt after using ChatGPT for the first time,” wrote technologist reporter Kevin Roose.
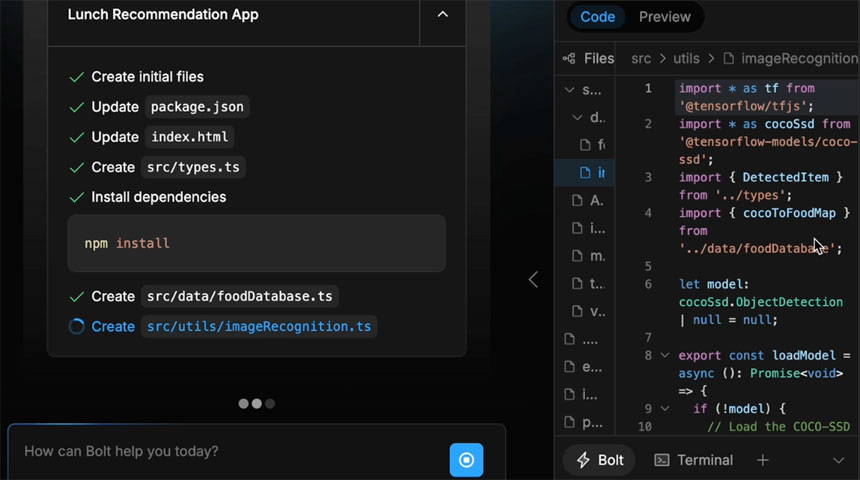
In the last year, new tools, such as Cursor, Replit, Bolt, and Lovable, have been built to use more powerful AI models, enabling neophytes to program like pros, as shown in the video above.
After the user’s prompt, the tool creates a design, decides on the best software packages and programming languages, and builds a working prototype.
Users can suggest tweaks and revisions and then deploy their new product to the web or run it on their computers. Depending on the project’s complexity, the process takes a few minutes or several hours.
Most of the products allow limited free use, with paid tiers that unlock better features and the ability to build more things.
Not all vibecoding experiments have been successful, and occasionally, AI makes mistakes.
For now, these tools are for hobby projects or even junior programmers, but not essential tasks.
the 14 most valuable skills in startups today:
it’s crazy that university doesn’t teach this:
1. attention arbitrage – spot which platforms are undercharging for reach and get the right creative in front of them
2. thumb-stopping content – understand how to make people stop…
Nvidia presented an open-source humanoid robot called Isaac GR00T N1 at its annual conference yesterday.
The company said it was “the world’s first open, fully customizable foundation model for generalized humanoid reasoning and skills.”
“The age of generalist robotics is here,” said Jensen Huang, founder and CEO of NVIDIA. “With Isaac GR00T N1 and new data-generation and robot-learning frameworks, robotics developers everywhere will open the next frontier in the age of AI.”
Newton, an open-source physics engine — under development with Google DeepMind and Disney Research — purpose-built for developing robots.
The GR00T N1 foundation model features a dual-system architecture inspired by human cognition. System 1 is a fast-thinking action model that mirrors human reflexes or intuition, while System 2 is a slow-thinking model for deliberate, methodical decision-making.
The chip company said GR00T N1 could generalize everyday tasks — such as grasping, moving objects with one or both arms, and transferring items from one arm to another — or perform multistep tasks requiring extended context and combinations of general skills. These capabilities can be applied to material handling, packaging, and inspection cases.
Developers and researchers can post-train GR00T N1 with real or synthetic data for their specific humanoid robot or task.
In his GTC keynote, Huang demonstrated 1X’s humanoid robot autonomously performing domestic tidying tasks using a post-trained policy built on GR00T N1. The robot’s autonomous capabilities are the result of an AI training collaboration between 1X and NVIDIA.
NVIDIA announced GR00T N1, the first fully customizable open-source humanoid robot foundation model, designed to advance general-purpose robotics.
⦿ A dual-system AI inspired by human cognition: System-1 handles fast, intuitive actions, while System-2 enables methodical… pic.twitter.com/qb3gVlMv1o
The 1EdTech Consortium (1EdTech) released the CLR Standard 2.0, its latest innovation in digital credential technology, during the organization’s Digital Credentials Summit, which took place this month in Phoenix, Arizona.
“With CLR Standard 2.0, we are making credentials more secure, portable, and universally verifiable, we are ensuring that every learner has the ability to own and share their achievements with confidence,” said Curtiss Barnes, CEO of 1EdTech.
The CLR Standard establishes a common way to package credential records in formal and informal learning, regardless of who provides them to the learner.
CLR 2.0 improves portability and verifiability, giving the earner control of their credentials by using rich human-readable and machine-verifiable metadata.
CLR 2.0 is also designed as Verifiable Credentials (VCs), as defined by the World Wide Web Consortium (W3C), and aligns with 1EdTech’s Open Badges 3.0 standard, making it even easier to share credentials between wallets.
Public and private universities have developed a critical portion of the nation’s research and scholarship in the last 75 years since the National Science Foundation (NSF) launch in 1950. Faculty-led researchers and students have spread doctoral education and become innovators and leaders of society and the world’s largest economy.
Of the over 2,000 research universities in the country, 146 are Carnegie R1 (doctoral universities with very high research intensity).
Universities collectively spent $97 billion on research, of which $54 billion was federal support. Twenty most prominent universities receive a third of the support.
But will the American research universities make it to their 100th birthday?
According to Dr Robert A Brown, President Emeritus and Computing and Data Sciences Professor at Boston University, various forces threaten the viability of U.S. research universities.
Among those forces, experts note the new political landscape, with the Trump administration’s announcements to cut research funds, the decline of college-age students, massive pedagogical and operational upheavals caused by AI, and the expectation that the cost of education will come down with chatbots and copilots replacing staff.
Professor Bryan Alexander assembled evidence of the adverse effects felt in the academic world after President Trump took office.
“Most of the Institute for Education Sciences (IES) unit, a research team that’s part of the National Center for Education Statistics (NCES), have been laid off. Nearly $1 billion in IES research contracts has been cut. More than $330 million was cut from the Center’s Regional Educational Laboratories and Equity Assistance Centers. At least thousands of students have seen internships with the federal government vanish, or at least become unclear if they will happen, due to cuts.”
Among other cuts, Bryan Alexander noted these:
• MIT, expecting federal losses of $100 million or more, suspended non-faculty hiring.
• The University of Louisville has ordered a hiring freeze, apparently across the board, until summer.
• North Carolina State University is going to implement a total hiring freeze.
• Columbia University’s medical school announced a hiring freeze.
• Northwestern University announced a 10% cut to non-personnel expenses.
The new administration cut $600 million in DEI-related campus grants.