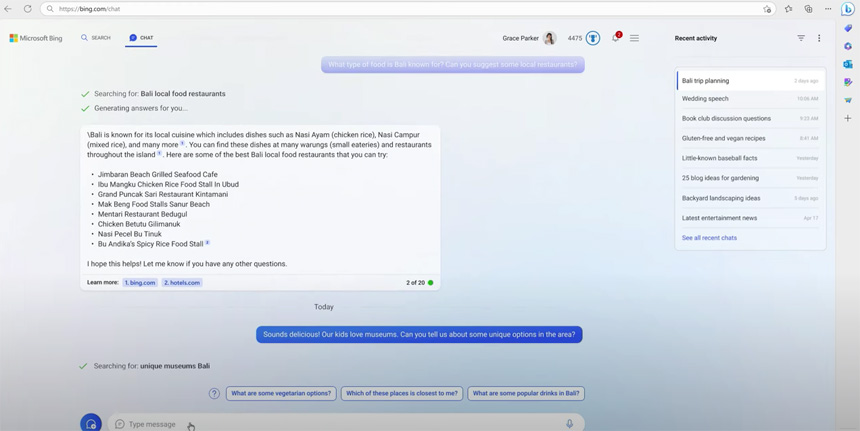
Microsoft announced this week it has opened up access to its Bing GPT-4 chatbot to anyone with an account, removing the waitlist. The chatbot originally launched in a private preview in February, and Microsoft has gradually been opening it up ever since.
The software giant is also massively upgrading Bing Chat and redesigning Edge with lots of new features, including image and video results, persistent chat and history, compose sidebar, Knowledge Cards and visual search, and plug-in support.
Microsoft is working with OpenTable to enable its plug-in for completing restaurant bookings within Bing Chat and WolframAlpha for generating visualizations.
According to Microsoft, in ninety days, Bing has grown to 100 million daily active users and people have created 200 million images with Bing Image Creator.
• “We aimed to tackle a universal problem with traditional search – that nearly half of all web searches go unanswered, resulting in billions of people’s searches falling short of the mark. We launched the new Bing to bring you better search results, answers to your questions, the ability to create and compose, and a new level of ease of use by being able to chat in natural language.”
• “Bing combines powerful large language models like Open AI’s GPT-4 with our immense search index for results that are current, cited, and conversational – something you can’t get anywhere else but on Bing. This is fundamentally changing the way people find information.”
A leaked document from a senior software engineer at Google noted that Google is losing its edge in artificial intelligence to the open-source community, where many independent researchers use AI technology to make rapid and unexpected advances.
“A third faction has been quietly eating our lunch. I’m talking, of course, about open source,” he said.
“The one clear winner in all of this is Meta. Because the leaked model [LLaMA] was theirs, they have effectively garnered an entire planet’s worth of free labor. Since most open-source innovation is happening on top of their architecture, there is nothing stopping them from directly incorporating it into their products.”
The engineer, Luke Sernau, published the document on an internal system at Google in early April.
Over the past few weeks, the document was shared thousands of times among Googlers, according to a person familiar with the matter, who asked not to be named because they were not authorized to discuss internal company matters.
On Thursday, the document below was published by an anonymous individual on a public Discord server. The only modifications are formatting and removing links to internal web pages. The document is only the opinion of a Google employee, not the entire firm.
We’ve done a lot of looking over our shoulders at OpenAI. Who will cross the next milestone? What will the next move be?
But the uncomfortable truth is, we aren’t positioned to win this arms race and neither is OpenAI. While we’ve been squabbling, a third faction has been quietly eating our lunch.
I’m talking, of course, about open source. Plainly put, they are lapping us. Things we consider “major open problems” are solved and in people’s hands today. Just to name a few:
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months. This has profound implications for us:
We have no secret sauce. Our best hope is to learn from and collaborate with what others are doing outside Google. We should prioritize enabling 3P integrations.
People will not pay for a restricted model when free, unrestricted alternatives are comparable in quality. We should consider where our value adds really is.
Giant models are slowing us down. In the long run, the best models are the ones that can be iterated upon quickly. We should make small variants more than an afterthought, now that we know what is possible in the <20B parameter regime.
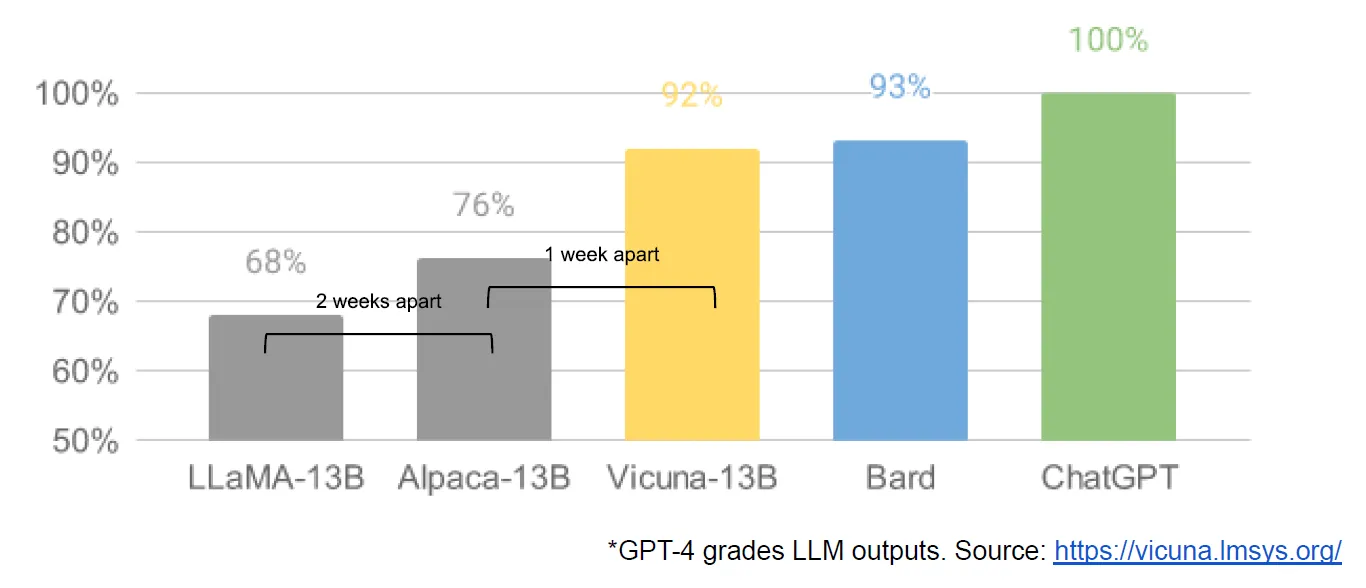
https://lmsys.org/blog/2023-03-30-vicuna/
What Happened
At the beginning of March, the open source community got their hands on their first really capable foundation model, as Meta’s LLaMA was leaked to the public. It had no instruction or conversation tuning, and no RLHF. Nonetheless, the community immediately understood the significance of what they had been given.
A tremendous outpouring of innovation followed, with just days between major developments (see The Timeline for the full breakdown). Here we are, barely a month later, and there are variants with instruction tuning, quantization, quality improvements, human evals, multimodality, RLHF, etc. etc. many of which build on each other.
Most importantly, they have solved the scaling problem to the extent that anyone can tinker. Many of the new ideas are from ordinary people. The barrier to entry for training and experimentation has dropped from the total output of a major research organization to one person, an evening, and a beefy laptop.
Why We Could Have Seen It Coming
In many ways, this shouldn’t be a surprise to anyone. The current renaissance in open-source LLMs comes hot on the heels of a renaissance in image generation. The similarities are not lost on the community, with many calling this the “Stable Diffusion moment” for LLMs.
In both cases, low-cost public involvement was enabled by a vastly cheaper mechanism for fine-tuning called low-rank adaptation, or LoRA, combined with a significant breakthrough in scale (latent diffusion for image synthesis, Chinchilla for LLMs). In both cases, access to a sufficiently high-quality model kicked off a flurry of ideas and iteration from individuals and institutions around the world. In both cases, this quickly outpaced the large players.
These contributions were pivotal in the image generation space, setting Stable Diffusion on a different path from Dall-E. Having an open model led to product integrations, marketplaces, user interfaces, and innovations that didn’t happen for Dall-E.
The effect was palpable: rapid domination in terms of cultural impact vs the OpenAI solution, which became increasingly irrelevant. Whether the same thing will happen for LLMs remains to be seen, but the broad structural elements are the same.
What We Missed
The innovations that powered open source’s recent successes directly solve problems we’re still struggling with. Paying more attention to their work could help us to avoid reinventing the wheel.
LoRA is an incredibly powerful technique we should probably be paying more attention to
LoRA works by representing model updates as low-rank factorizations, which reduces the size of the update matrices by a factor of up to several thousand. This allows model fine-tuning at a fraction of the cost and time. Being able to personalize a language model in a few hours on consumer hardware is a big deal, particularly for aspirations that involve incorporating new and diverse knowledge in near real-time. The fact that this technology exists is underexploited inside Google, even though it directly impacts some of our most ambitious projects.
Retraining models from scratch is the hard path
Part of what makes LoRA so effective is that – like other forms of fine-tuning – it’s stackable. Improvements like instruction tuning can be applied and then leveraged as other contributors add on dialogue, or reasoning, or tool use. While the individual fine tunings are low rank, their sum need not be, allowing full-rank updates to the model to accumulate over time.
This means that as new and better datasets and tasks become available, the model can be cheaply kept up to date, without ever having to pay the cost of a full run.
By contrast, training giant models from scratch not only throws away the pretraining, but also any iterative improvements that have been made on top. In the open source world, it doesn’t take long before these improvements dominate, making a full retrain extremely costly.
We should be thoughtful about whether each new application or idea really needs a whole new model. If we really do have major architectural improvements that preclude directly reusing model weights, then we should invest in more aggressive forms of distillation that allow us to retain as much of the previous generation’s capabilities as possible.
Large models aren’t more capable in the long run if we can iterate faster on small models
LoRA updates are very cheap to produce (~$100) for the most popular model sizes. This means that almost anyone with an idea can generate one and distribute it. Training times under a day are the norm. At that pace, it doesn’t take long before the cumulative effect of all of these fine-tunings overcomes starting off at a size disadvantage. Indeed, in terms of engineer-hours, the pace of improvement from these models vastly outstrips what we can do with our largest variants, and the best are already largely indistinguishable from ChatGPT. Focusing on maintaining some of the largest models on the planet actually puts us at a disadvantage.
Data quality scales better than data size
Many of these projects are saving time by training on small, highly curated datasets. This suggests there is some flexibility in data scaling laws. The existence of such datasets follows from the line of thinking in Data Doesn’t Do What You Think, and they are rapidly becoming the standard way to do training outside Google. These datasets are built using synthetic methods (e.g. filtering the best responses from an existing model) and scavenging from other projects, neither of which is dominant at Google. Fortunately, these high quality datasets are open source, so they are free to use.
Directly Competing With Open Source Is a Losing Proposition
This recent progress has direct, immediate implications for our business strategy. Who would pay for a Google product with usage restrictions if there is a free, high quality alternative without them?
And we should not expect to be able to catch up. The modern internet runs on open source for a reason. Open source has some significant advantages that we cannot replicate.
We need them more than they need us
Keeping our technology secret was always a tenuous proposition. Google researchers are leaving for other companies on a regular cadence, so we can assume they know everything we know, and will continue to for as long as that pipeline is open.
But holding on to a competitive advantage in technology becomes even harder now that cutting edge research in LLMs is affordable. Research institutions all over the world are building on each other’s work, exploring the solution space in a breadth-first way that far outstrips our own capacity. We can try to hold tightly to our secrets while outside innovation dilutes their value, or we can try to learn from each other.
Individuals are not constrained by licenses to the same degree as corporations
Much of this innovation is happening on top of the leaked model weights from Meta. While this will inevitably change as truly open models get better, the point is that they don’t have to wait. The legal cover afforded by “personal use” and the impracticality of prosecuting individuals means that individuals are getting access to these technologies while they are hot.
Being your own customer means you understand the use case
Browsing through the models that people are creating in the image generation space, there is a vast outpouring of creativity, from anime generators to HDR landscapes. These models are used and created by people who are deeply immersed in their particular subgenre, lending a depth of knowledge and empathy we cannot hope to match.
Owning the Ecosystem: Letting Open Source Work for Us
Paradoxically, the one clear winner in all of this is Meta. Because the leaked model was theirs, they have effectively garnered an entire planet’s worth of free labor. Since most open-source innovation is happening on top of their architecture, there is nothing stopping them from directly incorporating it into their products.
The value of owning the ecosystem cannot be overstated. Google itself has successfully used this paradigm in its open-source offerings, like Chrome and Android. By owning the platform where innovation happens, Google cements itself as a thought leader and direction-setter, earning the ability to shape the narrative on ideas that are larger than itself.
The more tightly we control our models, the more attractive we make open alternatives. Google and OpenAI have both gravitated defensively toward release patterns that allow them to retain tight control over how their models are used. But this control is a fiction. Anyone seeking to use LLMs for unsanctioned purposes can simply take their pick of the freely available models.
Google should establish itself a leader in the open source community, taking the lead by cooperating with, rather than ignoring, the broader conversation. This probably means taking some uncomfortable steps, like publishing the model weights for small ULM variants. This necessarily means relinquishing some control over our models. But this compromise is inevitable. We cannot hope to both drive innovation and control it.
Epilogue: What about OpenAI?
All this talk of open source can feel unfair given OpenAI’s current closed policy. Why do we have to share, if they won’t? But the fact of the matter is, we are already sharing everything with them in the form of the steady flow of poached senior researchers. Until we stem that tide, secrecy is a moot point.
And in the end, OpenAI doesn’t matter. They are making the same mistakes we are in their posture relative to open source, and their ability to maintain an edge is necessarily in question. Open source alternatives can and will eventually eclipse them unless they change their stance. In this respect, at least, we can make the first move.
The Timeline
Feb 24, 2023 – LLaMA is Launched
Meta launches LLaMA, open sourcing the code, but not the weights. At this point, LLaMA is not instruction or conversation tuned. Like many current models, it is a relatively small model (available at 7B, 13B, 33B, and 65B parameters) that has been trained for a relatively large amount of time, and is therefore quite capable relative to its size.
March 3, 2023 – The Inevitable Happens
Within a week, LLaMA is leaked to the public. The impact on the community cannot be overstated. Existing licenses prevent it from being used for commercial purposes, but suddenly anyone is able to experiment. From this point forward, innovations come hard and fast.
March 12, 2023 – Language models on a Toaster
A little over a week later, Artem Andreenko gets the model working on a Raspberry Pi. At this point the model runs too slowly to be practical because the weights must be paged in and out of memory. Nonetheless, this sets the stage for an onslaught of minification efforts.
March 13, 2023 – Fine Tuning on a Laptop
The next day, Stanford releases Alpaca, which adds instruction tuning to LLaMA. More important than the actual weights, however, was Eric Wang’s alpaca-lora repo, which used low rank fine-tuning to do this training “within hours on a single RTX 4090”.
Suddenly, anyone could fine-tune the model to do anything, kicking off a race to the bottom on low-budget fine-tuning projects. Papers proudly describe their total spend of a few hundred dollars. What’s more, the low rank updates can be distributed easily and separately from the original weights, making them independent of the original license from Meta. Anyone can share and apply them.
March 18, 2023 – Now It’s Fast
Georgi Gerganov uses 4 bit quantization to run LLaMA on a MacBook CPU. It is the first “no GPU” solution that is fast enough to be practical.
March 19, 2023 – A 13B model achieves “parity” with Bard
The next day, a cross-university collaboration releases Vicuna, and uses GPT-4-powered eval to provide qualitative comparisons of model outputs. While the evaluation method is suspect, the model is materially better than earlier variants. Training Cost: $300.
Notably, they were able to use data from ChatGPT while circumventing restrictions on its API – They simply sampled examples of “impressive” ChatGPT dialogue posted on sites like ShareGPT.
March 25, 2023 – Choose Your Own Model
Nomic creates GPT4All, which is both a model and, more importantly, an ecosystem. For the first time, we see models (including Vicuna) being gathered together in one place. Training Cost: $100.
March 28, 2023 – Open Source GPT-3
Cerebras (not to be confused with our own Cerebra) trains the GPT-3 architecture using the optimal compute schedule implied by Chinchilla, and the optimal scaling implied by μ-parameterization. This outperforms existing GPT-3 clones by a wide margin, and represents the first confirmed use of μ-parameterization “in the wild”. These models are trained from scratch, meaning the community is no longer dependent on LLaMA.
March 28, 2023 – Multimodal Training in One Hour
Using a novel Parameter Efficient Fine Tuning (PEFT) technique, LLaMA-Adapter introduces instruction tuning and multimodality in one hour of training. Impressively, they do so with just 1.2M learnable parameters. The model achieves a new SOTA on multimodal ScienceQA.
April 3, 2023 – Real Humans Can’t Tell the Difference Between a 13B Open Model and ChatGPT
Berkeley launches Koala, a dialogue model trained entirely using freely available data.
They take the crucial step of measuring real human preferences between their model and ChatGPT. While ChatGPT still holds a slight edge, more than 50% of the time users either prefer Koala or have no preference. Training Cost: $100.
April 15, 2023 – Open Source RLHF at ChatGPT Levels
Open Assistant launches a model and, more importantly, a dataset for Alignment via RLHF. Their model is close (48.3% vs. 51.7%) to ChatGPT in terms of human preference. In addition to LLaMA, they show that this dataset can be applied to Pythia-12B, giving people the option to use a fully open stack to run the model. Moreover, because the dataset is publicly available, it takes RLHF from unachievable to cheap and easy for small experimenters.
My thoughts on the now famous Google leak doc: https://t.co/hK2KcMTEDB
1. Open source AI is winning. I agree, and that is great for the world and for a competitive ecosystem. In LLMs we’re not there, but we just got OpenClip to beat openAI Clip and Stable diffusion is better than…
The Biden Administration announced actions to deal with AI-related risks and opportunities and make sure companies deploy safe products.
Yesterday, Vice President Harris and senior Administration officials met with CEOs of Alphabet, Anthropic, Microsoft, and OpenAI encouraging them to apply safeguards that mitigate risks and potential harms to individuals and society [In the picture, Sundar Pichai, Google’s CEO, left, and Sam Altman, OpenAI’s CEO, arriving at the White House.]
More engagements are planned with corporations, researchers, civil rights organizations, not-for-profit organizations, communities, international partners, and others on critical AI issues.
In addition, the National Science Foundation announced $140 million in funding to launch seven new National AI Research Institutes, that will advance AI R&D to drive breakthroughs in critical areas, including climate, agriculture, energy, public health, education, and cybersecurity.
This investment will bring the total number of Institutes to 25 across the country, and extend the network of organizations involved to nearly every state.
The Administration will promote an independent commitment from leading AI developers, including Anthropic, Google, Hugging Face, Microsoft, NVIDIA, OpenAI, and Stability AI, will participate in a public evaluation of AI systems by Scale AI—at the AI Village at DEFCON 31.
“This independent exercise will provide critical information to researchers and the public about the impacts of these models, and will enable AI companies and developers to take steps to fix issues found in those models. Testing of AI models independent of government or the companies that have developed them is an important component in their effective evaluation,” said the Biden Administration.
Discussing the impacts of artificial intelligence, Steve Wozniak, Apple’s co-founder said on CNN that he was not concerned. [See video below]
“I am confident AI will be used by bad actors, and yes it will cause real damage,” Microsoft Corp. Chief Economist Michael Schwarz said during a World Economic Forum panel in Geneva on Wednesday.
“It can do a lot damage in the hands of spammers with elections and so on,” he added.
His statements came one day after the “Godfather of AI”, Dr. Geoffrey Hinton [in the picture], quit Google after warning of the dangers of AI ahead, as The New York Times reported.
Dr. Geoffrey Hinton, an artificial intelligence pioneer, announced he was regretting his life’s work and was leaving Google, where he has worked for more than a decade so that he freely shares his concern that artificial intelligence could cause the world serious harm.
On Monday he joined a growing number of critics who say those companies are racing toward danger with their aggressive campaign to create products based on generative artificial intelligence, the technology that powers popular chatbots like ChatGPT.
“I console myself with the normal excuse: If I hadn’t done it, somebody else would have,” Dr. Hinton said to The New York Times.
“Dr. Hinton’s journey from A.I. groundbreaker to doomsayer marks a remarkable moment for the technology industry at perhaps its most important inflection point in decades,” wrote the paper.
Many industry insiders say Generative A.I. can already be a tool for misinformation, soon, it could be a risk to jobs, and somewhere down the line, it could be a risk to humanity.
“It is hard to see how you can prevent the bad actors from using it for bad things,” Dr. Hinton said.
Google spent $44 million to acquire a company started by Dr. Hinton and his two students. And their system led to the creation of increasingly powerful technologies, including new chatbots like ChatGPT and Google Bard.
In 2018, Dr. Hinton and two other longtime collaborators received the Turing Award, often called “the Nobel Prize of computing,” for their work on neural networks.
Dr. Hinton believes that the race between Google and Microsoft and others will escalate into a global race that will not stop without some sort of global regulation.
“The best hope is for the world’s leading scientists to collaborate on ways of controlling the technology.”
Palo Alto-based startup Inflection AI, run by Ex-DeepMind leaders, is launching a conversational chatbot named PI (for “personal intelligence”) that plays the active listener role and acts in a more personal way over back-and-forth dialog.
“It’s really a new class of AI — it’s distinct in the sense that a personal AI is one that really works for you as the individual,” said Mustafa Suleyman, CEO of Inflection AI, [in the picture below].
“Pi will help you organize your schedule, prep for meetings, and learn new skills,” he added. “It’s AI that is singularly aligned to your interests, that’s really yours.”
Built on one of Inflection’s in-house large language models, Pi is designed to speak casually as if conversing with an attentive friend while giving fact-based answers. Its company Inflection AI has raised $225 million to date.
The market is now being flooded with all kinds of bots, with the industry shipping new models and products in an accelerated way.
Last week, Suleyman’s former colleague at Google, AI “godfather” Geoffrey Hinton, announced he quit his job at Google to be able to speak more freely about AI’s dangers. “Look at how it was five years ago and how it is now,” Hinton toldThe New York Times. “Take the difference and propagate it forward. That’s scary.”
Suleyman’s previous company, DeepMind, was acquired by Google in 2014 to form the backbone of much of the company’s AI research — and the industry’s — ever since.
Structured as a public benefit corporation, Inflection employs about 30 people today, with Hoffman spending about one day per week with the company, according to Suleyman.
Inflection plans to offer Pi for free for now, with no token restrictions. Like OpenAI, Inflection uses Microsoft Azure for its cloud infrastructure.
“Through 10 or 20 such exchanges, Pi can tease out what a user really wants to know, or is hoping to talk through, more like a sounding board than a repackaged Wikipedia answer,” Suleyman said to Forbes.
Unlike other chatbots, Pi remembers a hundred turns of conversation with logged-in users across platforms, including WhatsApp, SMS messages, Facebook messages, and Instagram.
It also detects when users appear to be agitated or frustrated, and tweak its tone of responses, Suleyman said.
California-based Chegg (CHGG.N), which provides online study guides, saw its shares tumble after the company admitted that ChatGPT is hurting its growth.
Its revenue would be between $175 million and $178 million this quarter, far below the analyst consensus estimate of $193.6 million.
Chegg shares were down 48.41% to $9.06 during Tuesday trading. That means nearly $1 billion in market valuation.
“In the first part of the year, we saw no noticeable impact from ChatGPT on our new account growth and we were meeting expectations on new sign-ups,” CEO Dan Rosensweig said during the earnings call this Monday. “However, since March we saw a significant spike in student interest in ChatGPT. We now believe it’s having an impact on our new customer growth rate.”
Chegg is developing its own AI assistant, CheggMate, which is meant to help students with their homework. The product is built in collaboration with OpenAI. However, analysts estimate that the impact of the product is uncertain.
Across the education sector share fell sharply on Tuesday as
Overall, investors bet that artificial intelligence could upend business models in the education sector.
Pearson’s share fell by 15% while language-learning platform Duolingo was down by 10%, Coursera by 6.68%, 2U by 15.32%, and Udemy by 5%.
Venture Capital firms — including Tiger Global, Sequoia Capital, Andreessen Horowitz, Thrive, and K2 Global — have put in over $300 million at a valuation of $27 billion – $29 billion in OpenAI, TechCrunch reported.
Outside investors now own more than 30% of OpenAI. The company declined to comment or confirm the story. This is separate from the $10 billion investment from Microsoft, which has integrated OpenAI’s APIs with its Azure infrastructure and Office 365 productivity suite.
OpenAI’s ChatGPT has been a hit, with more than 1 billion visitors to its website in February, says SimilarWeb.
In addition, hundreds of businesses have started deploying GPT and ChatGPT into their products and services.
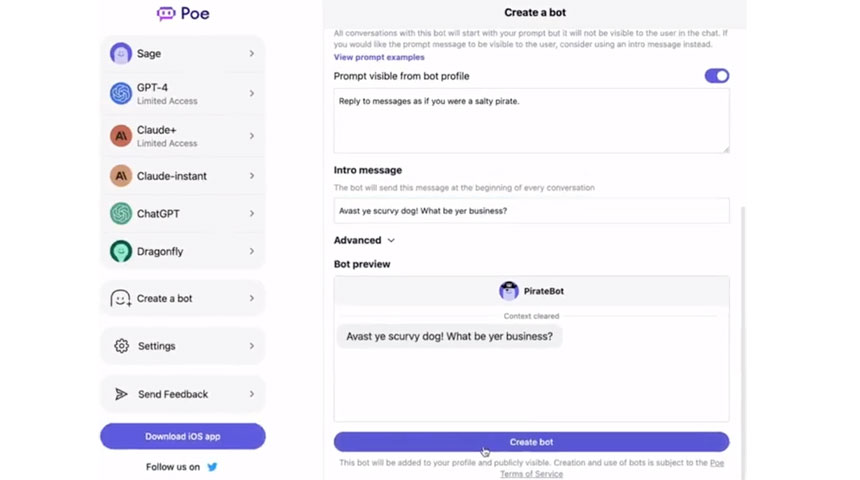
Q&A site Quora issued this week a new feature on its chatbot Poe that allow users to make their own chatbot based on a short text prompt and an existing bot, like ChatGPT, as the base.
Poe is the latest product from Quora as the company tries to expand into the search market by allowing consumers to play with technologies like OpenAI and Anthropic via simple mobile interfaces.
The new chatbot offers the ability for users to create their own bots using prompts — that is, adding text to direct a chatbot to perform as a favorite author, in a particular format, or aimed at a certain audience, among other things. Poe targets a new creator class within the field of prompt engineering.
Once created, the chatbot, based on either Claude or ChatGPT, will have its own unique URL (poe.com/botname). Users will access the bots via Poe’s iOS app or Android app on mobile or via its desktop web interface.
“It’s amazing how much value prompting can unlock from language models,” Quora CEO Adam D’Angelo said.
Quora plans to offer bot creators feedback about how people are using their the tool, along with an API that would allow anyone to host more complex bots from a server they operate potential. It’d a new business for Quora, as well.
To date, the mobile app version of Poe has 1.17 million installs and has generated $520,000 in gross revenue, according to app intelligence firm data.ai. The app is currently ranked No. 32 in the Productivity category on the App Store.
We are launching a new feature on Poe today: user-created bots. This initially allows anyone to create a new bot based on a short text prompt and an existing bot used as a base. We currently support Claude instant and ChatGPT as base bots. pic.twitter.com/Fr2Leoum8v
The learning platform Chegg (NYSE: CHGG) announced the launch of CheggMate, an AI conversational study companion built with OpenAI’s GPT-4, in May 2023.
The Santa Clara, California – based company explained that CheggMate will deliver personalized learning pathways, tailor-made quizzes and tests, and help guide for each student’s journey.
Students will be able to input a written text, photo, math query, or diagram in order to get answers, drill down into concepts they don’t understand, or master subjects.
“CheggMate will enable students to have an instantaneous AI conversation that is personalized to their learning style and needs, supported by our substantial proven and reliable content library,” said Dan Rosensweig, CEO & President of Chegg, Inc.
“We believe AI has the potential to provide tailored learning experiences to everyone and improve the way people around the world learn,” said Sam Altman, CEO of OpenAI. “We are very excited to work with Chegg, given their history as the leading student-first learning platform.”
“Chegg understands learners like no one else. We are building generative AI into our powerful and proprietary learning tools to support students’ active engagement in their learning process,” said Nina Huntemann, Ph.D, Chief Academic Officer of Chegg Inc.
Chegg’s personalized AI companion will offer the ability for students to pick up exactly where they left off or begin new learning interactions at any time, according to the company.
The company plans to open a limited access of CheggMate in May 2023.
Bethesda, Maryland-based training software company iLearningEngines Inc has agreed to go public on Nasdaq through a merger with blank-check company Arrowroot Acquisition Corp (ARRW.O) in a SPAC deal that values the combined company at $1.4 billion.
The deal will provide iLearningEngines with $143 million in gross proceeds, some of which will be used for future acquisitions.
This publicly traded special-purpose acquisition company is sponsored by Arrowroot Capital, a 10-year-old private equity firm specializing in enterprise software.
iLearningEngines supplies companies with personalized training materials using AI-powered automation tools and software.
Founded in 2010, the company builds “Knowledge Clouds” from an organization’s internal and external content and data, creating a central repository of all enterprise intellectual property. Then, it distributes knowledge into enterprise workflows in order to drive autonomous learning, intelligent decision making, and process automation.
The company is a profitable $300 million annual revenue business that provides services to companies in 12 core verticals, including industries like oil & gas, education, healthcare and insurance.
Arrowroot Acquisition Corp raised $290 million through its initial public offering in 2021, with the aim of merging with companies in the enterprise software sector.
iLearningEngines, a company with over 100,000 engineering research and development hours invested in its platform, priced the deal at 3.3x estimated 2023 revenue.
The combined company will continue to be led by iLearningEngines’ existing CEO and founder, Harish Chidambaran.
Artificial intelligence (AI) and machine learning (ML) startups globally have raised about $12.1 billion so far this year, according to PitchBook.
.