IBL News | New York
OpenAI created an in-house, internal-only AI data agent built specifically around OpenAI’s data, permissions, and workflows, which reasons on its own platform to get answers quickly, correctly, and with the right context. It helps answer how to evaluate launches and understand business health through natural language.
This data agent serves over 3,500 internal users, spanning over 600 petabytes of data across 70k datasets, letting employees go from question to insight in minutes, not days.
For employees, the agent is available as a Slack agent, via a web interface, in IDEs, in the Codex CLI via MCP, and directly in OpenAI’s internal ChatGPT app via a MCP connector.
The agent can access Slack, Google Docs, and Notion, which capture critical company context, including launches, reliability incidents, internal codenames and tools, and the canonical definitions and computation logic for key metrics.
These documents are ingested, embedded, and stored with metadata and permissions. A retrieval service handles access control and caching at runtime, enabling the agent to efficiently and safely pull in this information.
The company is disclosing how this AI data agent is used to support day-to-day work across its teams.
These tools used by OpenAI are Codex, its GPT‑5 flagship model, the Evals API, and the Embeddings API , available to developers everywhere.
The data agent combines Codex-powered table-level knowledge with product and organizational context. Its continuous learning memory system means it also improves with every turn.
Teams across Engineering, Data Science, Go-To-Market, Finance, and Research at OpenAI lean on the agent to answer high-impact data questions.
The agent covers the full analytics workflow: data discovery, SQL queries, and notebook and report publishing. It understands internal company knowledge, can search the web for external information, and improves over time through learned usage and memory.
High-quality answers depend on rich, accurate context. The agent without context memory is unable to query effectively.
As one internal user put it:
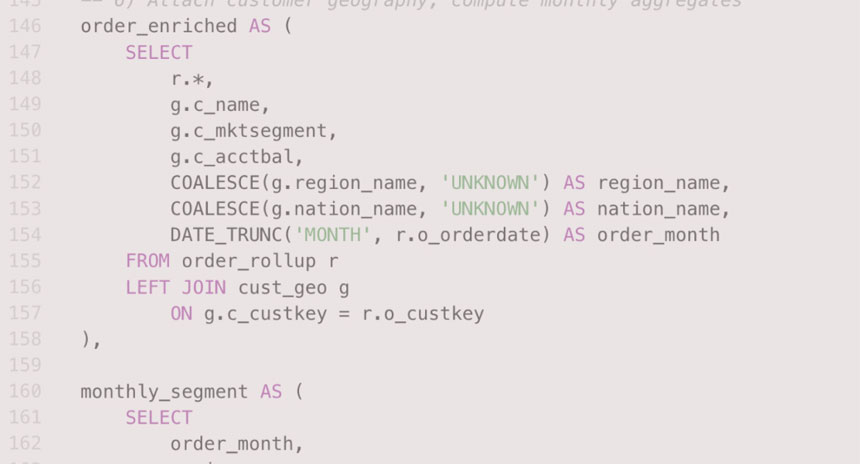
An internal user put it this way, “Even with the correct tables selected, producing correct results can be challenging. Analysts must reason about table data and table relationships to ensure transformations and filters are applied correctly. Common failure modes—many-to-many joins, filter pushdown errors, and unhandled nulls—can silently invalidate results. At OpenAI’s scale, analysts should not have to sink time into debugging SQL semantics or query performance: their focus should be on defining metrics, validating assumptions, and making data-driven decisions. This SQL statement is 180+ lines long. It’s not easy to know if we’re joining the right tables and querying the right columns.”