IBL News | New York
Llama open-source AI model is increasingly used by U.S. government agencies, contractors in national security, and large companies such as Accenture, AWS, Azure, Anduril, Booz Allen, Databricks, Deloitte, IBM, Leidos, Lockheed Martin, Microsoft, Oracle, Palantir, Scale AI, and Snowflake.
Meta talked publicly about it to combat the perception that it is aiding foreign adversaries like China. Last week, Reuters reported that Chinese research scientists linked to the People’s Liberation Army (PLA), the military wing of China’s ruling party, used an older Llama model, Llama 2, to develop a tool for defense applications.
“These Llama uses will also help establish U.S. open-source standards in the global race for AI leadership,” said the company.
“Also, open-source systems have helped to accelerate defense research and high-end computing, identify security vulnerabilities, and improve communication between disparate systems.”
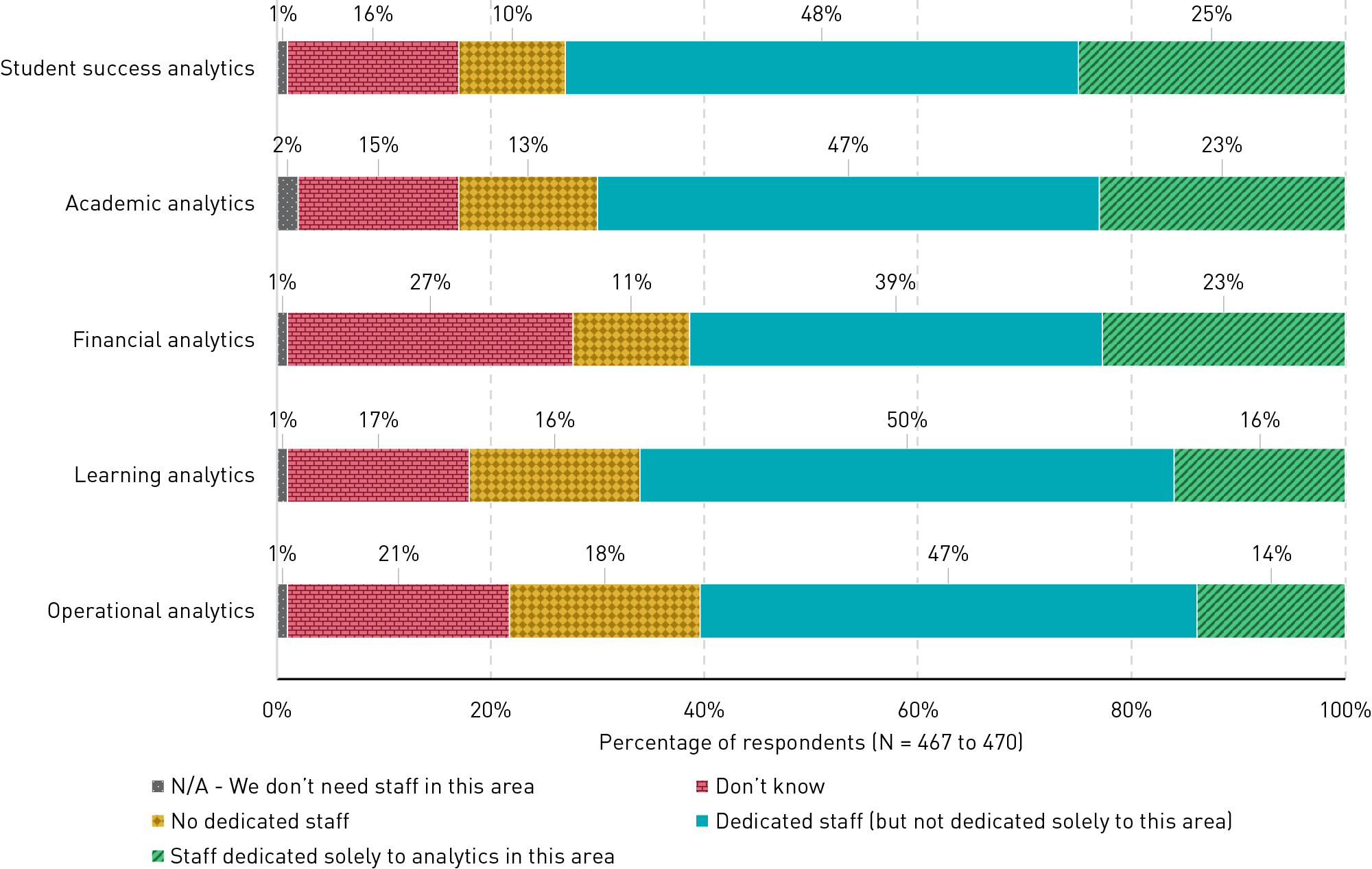
• Lockheed Martin incorporated Llama into its AI Factory, accelerating various use cases such as code generation, data analysis, and enhancing business processes.
Scale Ai is fine-tuning Llama to support specific national security team missions, such as planning operations and identifying adversaries’ vulnerabilities.
Meta believes “a global open-source standard for AI models is likely to emerge, as it has with technologies like Linux and Android.”