IBL News | New York
OpenAI launched the full version of GPT-5.5-Cyber this week, a model designed to hunt down and patch software vulnerabilities, with capabilities similar to those of Anthropic’s Mythos and Fable 5. However, OpenAI’s cyber model never drew a ban.
Researchers say the same vulnerability-hunting runs in GPT-5.5, Claude Opus, and other models.
At the time of release, Anthropic said its capabilities were too dangerous to ship. It also spent the month fighting the White House.
Meanwhile, OpenAI, well-connected in Washington, D.C., has said nothing during the launch. Moreover, it hired a co-author of Trump’s AI plan last week.
We’re expanding Daybreak to help democratize patching vulnerable software at machine speed.
To discover and generate patches for critical vulnerabilities in major browsers, network infrastructure, and operating systems such as FreeBSD and the Linux kernel, OpenAI has released:
- An update to the Codex Security plugin.
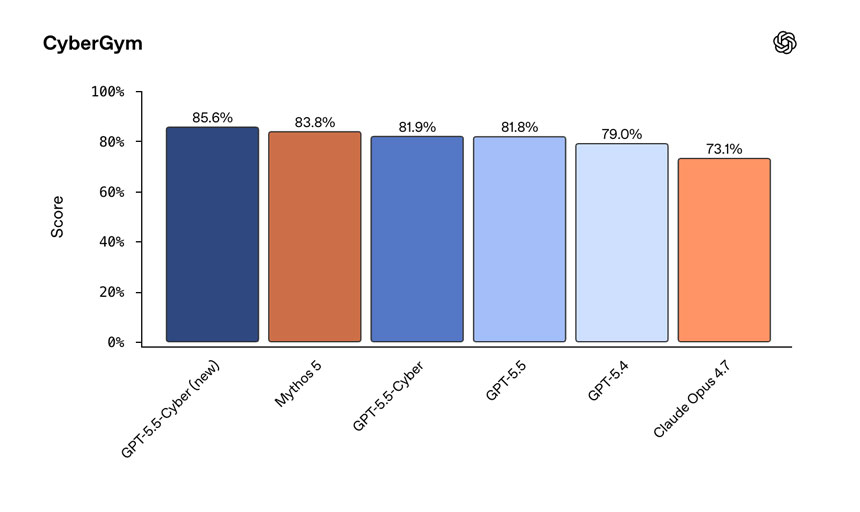
- GPT‑5.5‑Cyber, a model that sets a performance on CyberGym of 85.6% compared with 81.8% for GPT‑5.5. [See graphic above]
- Daybreak Cyber Partner Program.
- Patch the Planet: an initiative founded with Trail of Bits in collaboration with HackerOne, Calif researchers, and maintainers to help widely used open-source projects move from findings to fixes.
Frontier AI models have been increasingly accelerating the discovery of vulnerabilities. Now, defenders are overwhelmed with the number of vulnerabilities found. Patching vulnerabilities is a bottleneck now.
Models can navigate large codebases, reason through attack paths, validate hypotheses, and surface security issues that might otherwise stay hidden. Defenders absolutely need access to these capabilities and tools to fix what models can find now before attackers do.
Beyond vulnerability reports, the key is to validate the issue, understand its impact, develop and test a patch, coordinate disclosure, and help teams deploy the fix.
OpenAI revealed that since it launched the Codex Security cloud in research preview in March, it has scanned over 30 million commits across more than 30,000 codebases; human reviewers have manually marked more than 70,000 findings as fixed, and over 500,000 findings have been automatically determined to be fixed.